# Descompactando o arquivo necessário do ZIP:if (!file.exists("flights.csv")) {unzip("archive.zip", files ="flights.csv")}
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsimport calendarfrom datetime import datetime# AVISO: O processamento deste código pode demorar alguns minutos!def get_stats(chunk, pos=None):# Filtrar companhias de interesse subset = chunk[chunk["AIRLINE"].isin(["AA", "DL", "UA", "US"])]# Remover NAs subset = subset.dropna(subset=["ARRIVAL_DELAY", "YEAR", "MONTH", "DAY"])# Calcular estatísticas stats = ( subset.groupby(["YEAR", "MONTH", "DAY", "AIRLINE"]) .agg( n_total=("ARRIVAL_DELAY", "size"), n_atrasados=("ARRIVAL_DELAY", lambda x: (x >10).sum()) ) .reset_index() )return stats# Colunas utilizadascolunas_interesse = ["YEAR", "MONTH", "DAY", "AIRLINE", "ARRIVAL_DELAY"]# ALTERAÇÃO: Ler o arquivo CSV já descompactado.file="flights.csv"chunksize =100000lista_chunks = []# Este loop lê o arquivo CSV grande em pedaços de 100.000 linhas# para não sobrecarregar a memória RAM.print("Iniciando leitura e processamento dos chunks...")
Iniciando leitura e processamento dos chunks...
for chunk in pd.read_csv(file, usecols=colunas_interesse, chunksize=chunksize): stats_parciais = get_stats(chunk) lista_chunks.append(stats_parciais)print("Processamento dos chunks finalizado.")
Processamento dos chunks finalizado.
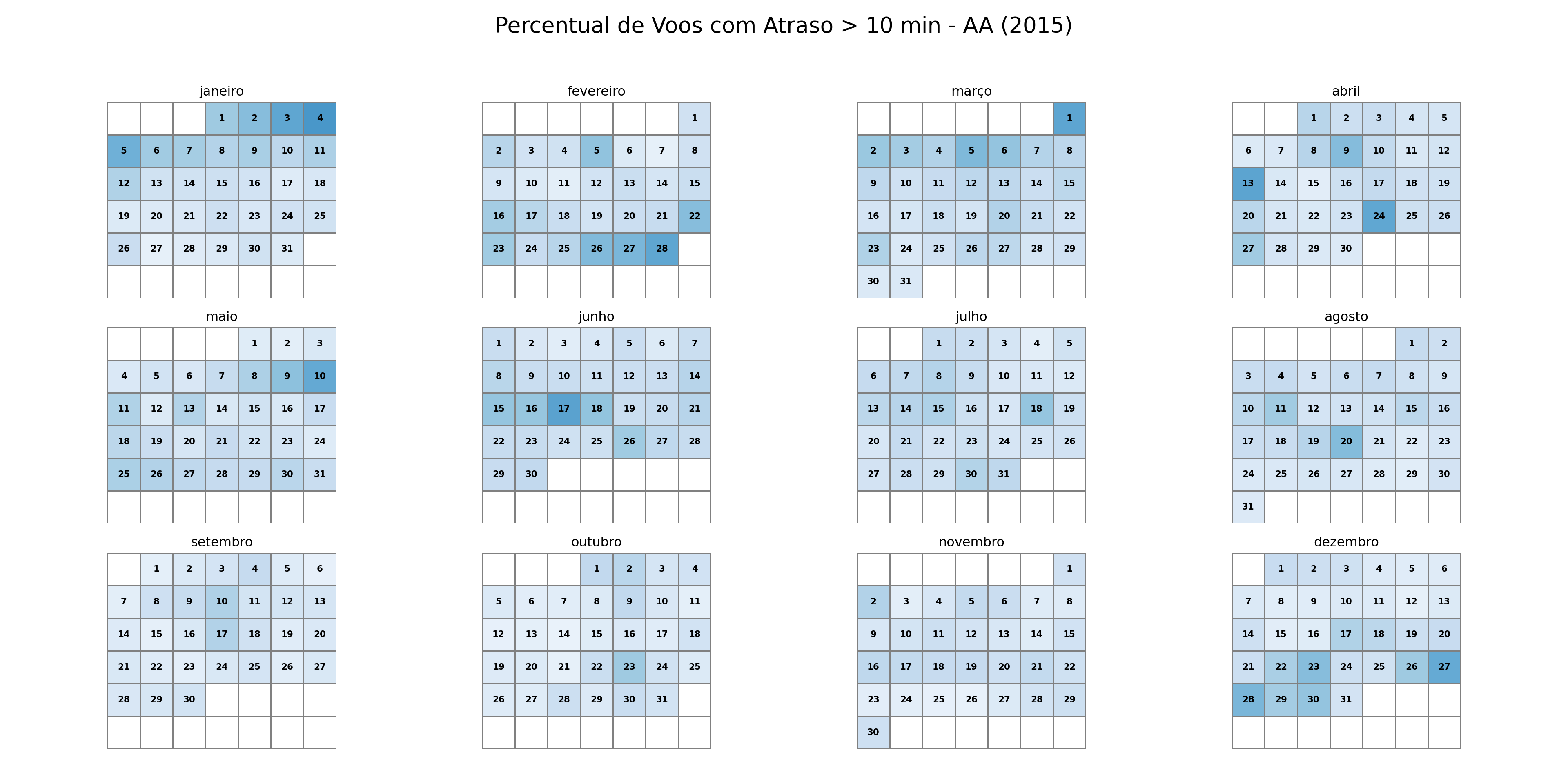
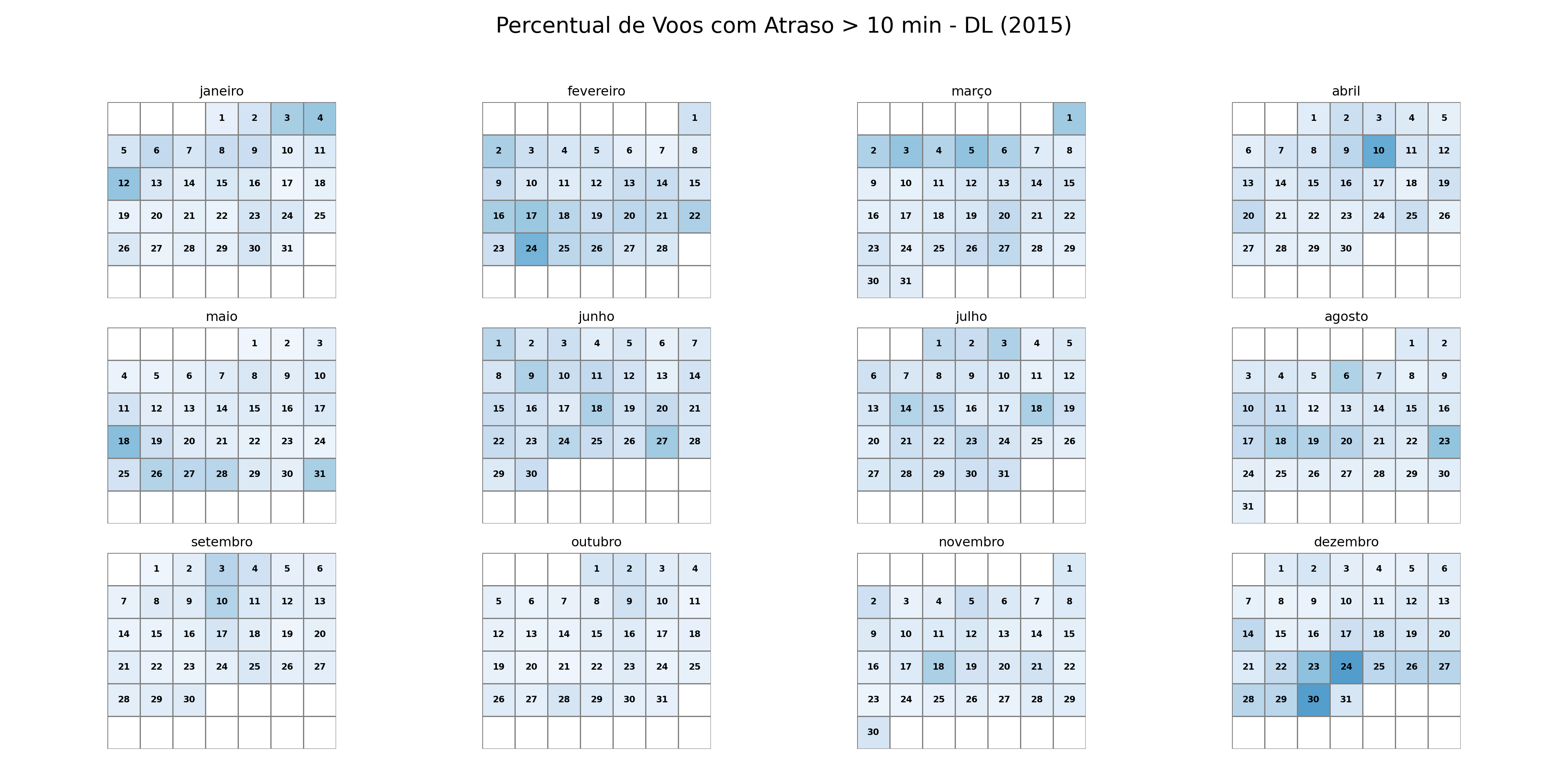
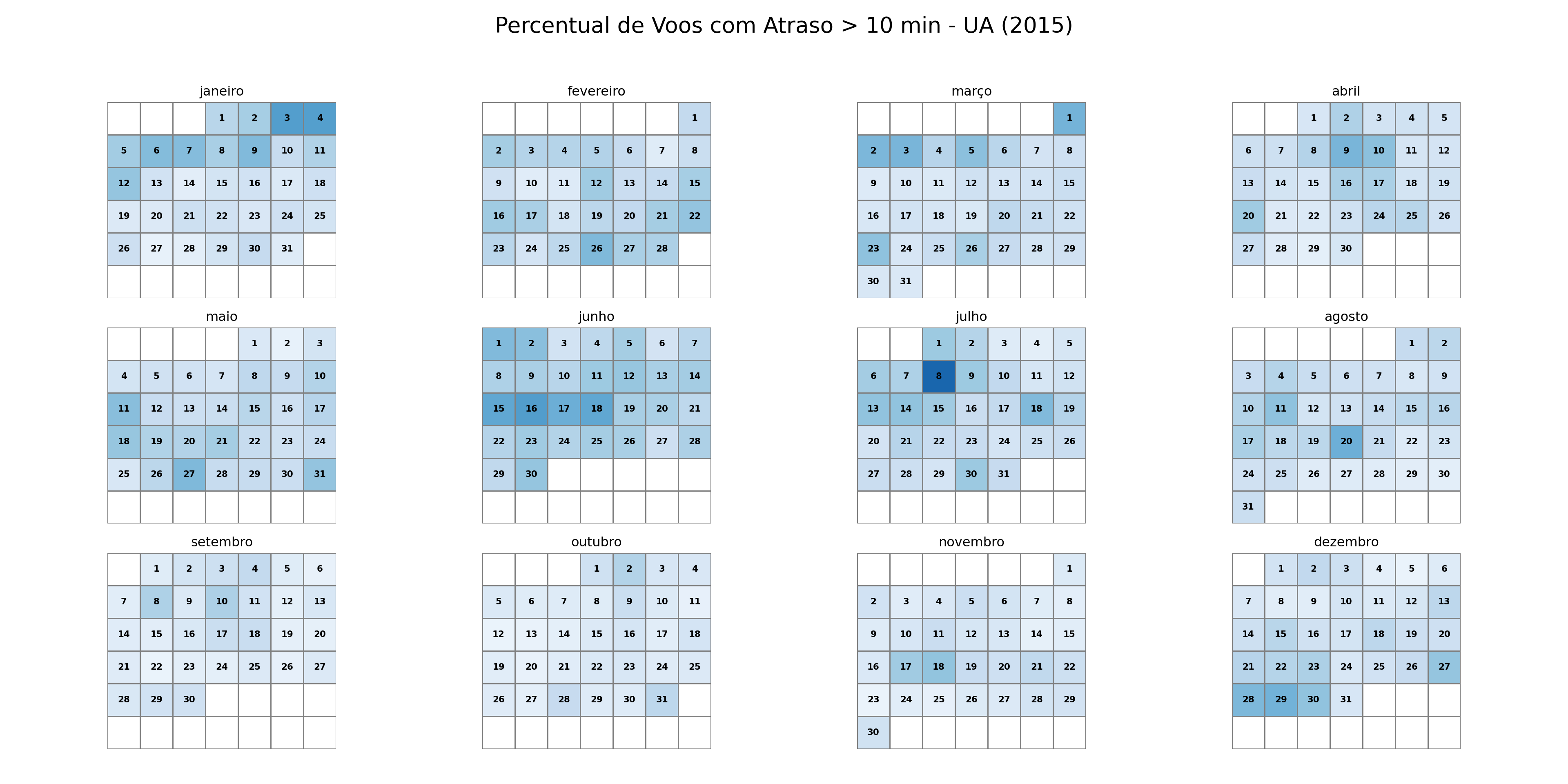
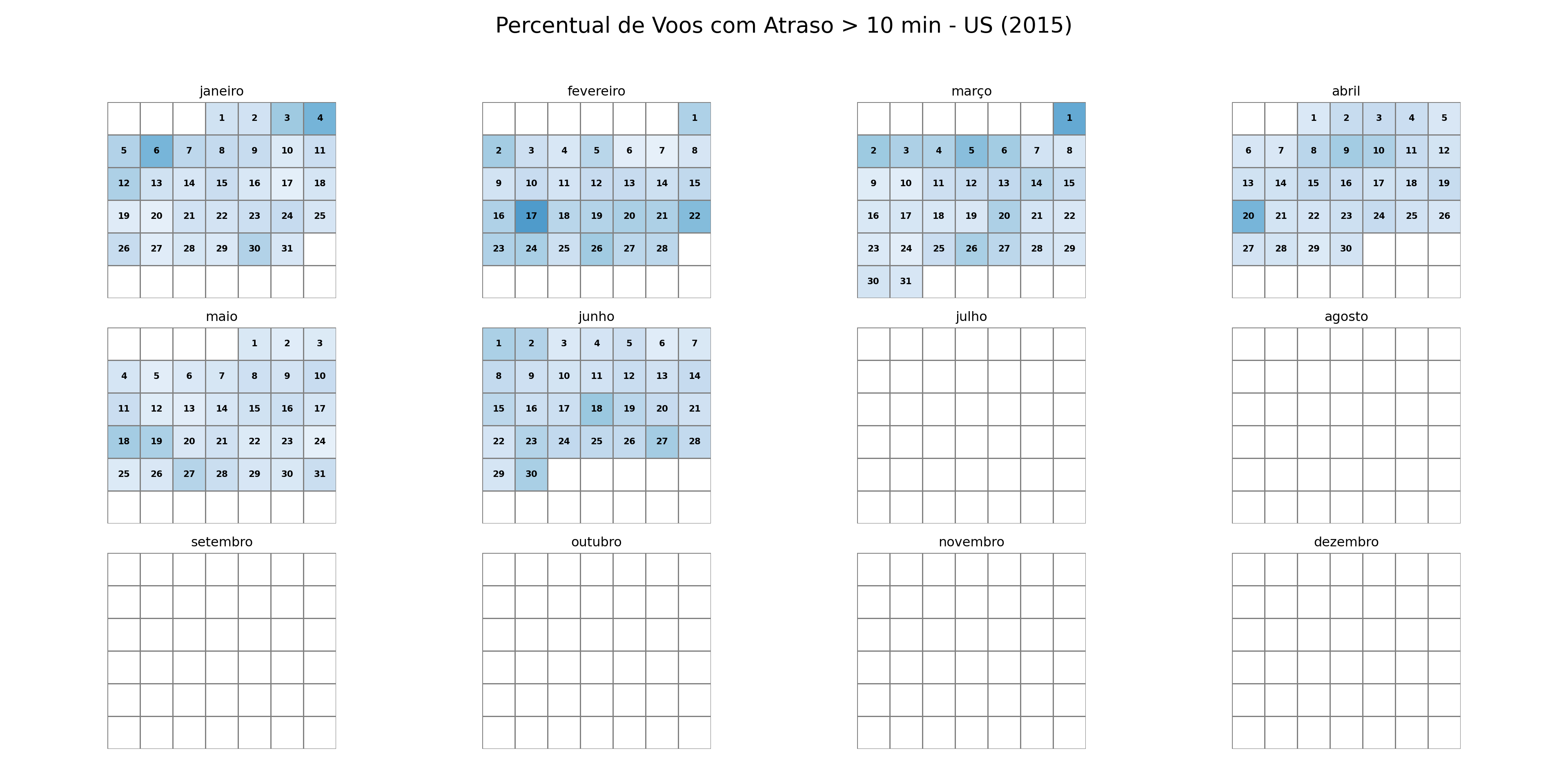
stats_parciais = pd.concat(lista_chunks, ignore_index=True)# Função para agregar as estatísticas de todos os chunksdef compute_stats(stats): stats_finais = ( stats.groupby(["YEAR", "MONTH", "DAY", "AIRLINE"]) .agg( n_total=("n_total", "sum"), n_atrasados=("n_atrasados", "sum") ) .reset_index() ) stats_finais["Data"] = pd.to_datetime( stats_finais[["YEAR", "MONTH", "DAY"]] ) stats_finais["Perc"] = stats_finais["n_atrasados"] / stats_finais["n_total"] stats_finais["Cia"] = stats_finais["AIRLINE"]return stats_finais[["Cia", "Data", "Perc"]]stats_finais = compute_stats(stats_parciais)# Função para plotar o calendário de atrasosdef plot_calendar(stats, cia, year=2015): df = stats[(stats["Cia"] == cia) & (stats["Data"].dt.year == year)].copy() df["Month"] = df["Data"].dt.month df["Day"] = df["Data"].dt.day fig, axes = plt.subplots(3, 4, figsize=(20, 10)) fig.patch.set_facecolor('white') # Define o fundo da figura como brancofor month inrange(1, 13): ax = axes[(month -1) //4, (month -1) %4] month_days = calendar.monthrange(year, month)[1] month_df = df[df["Month"] == month] first_weekday = calendar.monthrange(year, month)[0] data = np.full((6, 7), np.nan) day_labels = np.full((6, 7), "", dtype=object)for _, row in month_df.iterrows(): day_num = row["Day"]# Posição no calendário: (dia + primeiro_dia_da_semana - 1) total_pos = day_num + first_weekday -1 week = total_pos //7 weekday = total_pos %7# Correção para garantir que não saia do arrayif week <6: data[week, weekday] = row["Perc"] day_labels[week, weekday] =str(day_num)# Heatmap sns.heatmap( data, cmap="Blues", cbar=False, ax=ax, linewidths=0.5, linecolor="gray", square=True, vmin=0, vmax=1, annot=day_labels, # Usa o array de dias como anotação fmt="", # Formato vazio para que os números sejam mostrados como strings annot_kws={"color": "black", "fontsize": 8, "weight": "bold"} ) ax.set_title(calendar.month_name[month]) ax.set_xticks([]) ax.set_yticks([]) fig.suptitle(f"Percentual de Voos com Atraso > 10 min - {cia} ({year})", fontsize=20) plt.tight_layout(rect=[0, 0.03, 1, 0.95]) # Ajusta o layout para o título principal plt.show()# Gerar os gráficos para cada companhia aéreaplot_calendar(stats_finais, "AA", 2015)